LeNet-5 (1998)
Philosophy: “Learning hierarchy from pixels to characters”
LeNet-5 introduced the convolution-pooling pattern, enabling neural nets to learn shift-invariant features directly from raw data rather than handcrafted. It symbolized the first step in automating visual representation learning.
LeNet Block Architecture
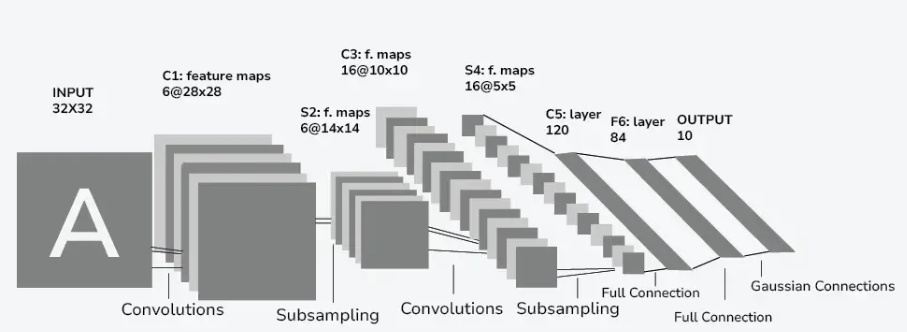
Philosophy in Action: LeNet 5’s Foundational Proof
1. Hierarchical Feature Learning—From Pixels to Patterns
LeNet 5 was groundbreaking because it automatically learned feature hierarchies. Early layers captured simple shapes; middle layers abstracted patterns like strokes; final layers combined these into digit-level concepts—demonstrating a clear philosophical journey from raw pixels to meaningful characters. By using learnable convolution kernels + pooled receptive fields, it encoded spatial hierarchies without manual feature engineering.
2. Shift-Invariance: Seeing Characters Anywhere
LeNet 5’s use of convolution + pooling achieved translation invariance, ensuring that a digit would be recognized regardless of its position in the image. This design mirrored the human visual cortical strategy of recognizing patterns regardless of small shifts. In practical terms, it gave the network the ability to generalize—recognizing handwritten digits even when centered imperfectly.
3. End-to-End Learning, Minimal Preprocessing
LeNet 5 was one of the first systems trained completely end-to-end, from raw 32×32 pixel inputs to digit output, via backpropagation. This eliminated hand-crafted feature extraction and handcrafted filters: the model learned its own filters through optimization, embodying the philosophy of automation.
4. Real World Impact: Theory to Practice
LeNet 5 wasn’t just a lab experiment—it was deployed. It powered ATM check-reading systems at AT&T/NCR, processing tens of millions of checks daily by 2001. This dramatic real-world usage validated that the learned hierarchical features actually solved a complex, real problem
Synthesis: Philosophy Confirmed
| Philosophical Pillars vs. Evidence in LeNet 5 | |
|---|---|
| Philosophical Pillars | Evidence in LeNet 5 |
| Hierarchical Abstraction | Multi-layer conv → strokes/digits |
| Invariance & Robustness | Shared weights + pooling for shift-invariance |
| Self-Learned Representation | Gradient-trained filters from pixels to characters |
| Production Viability | Massive deployment in ATMs, 20M checks/day |
Philosophical Impact
LeNet 5 made manifest the ideal that visual perception can be learned, hierarchical, and automated—not hand-designed. In doing so, it laid the bedrock for every modern CNN architecture that followed, from AlexNet through to ResNet and Transformers.
Featured Paper: LeNet (1998)

“This paper introduced the modern convolutional neural network, capable of learning feature hierarchies directly from pixels. LeNet-5 made vision learning scalable and practical.”
lexNet (2012)
Philosophy: “Make deep feasible”
AlexNet proved that depth matters, but only with GPU power, ReLU activations, dropout, and data augmentation. It broke the computational barrier, showing deep learning could outperform prior methods and sparking the modern AI renaissance.
AlexNet Block Architecture
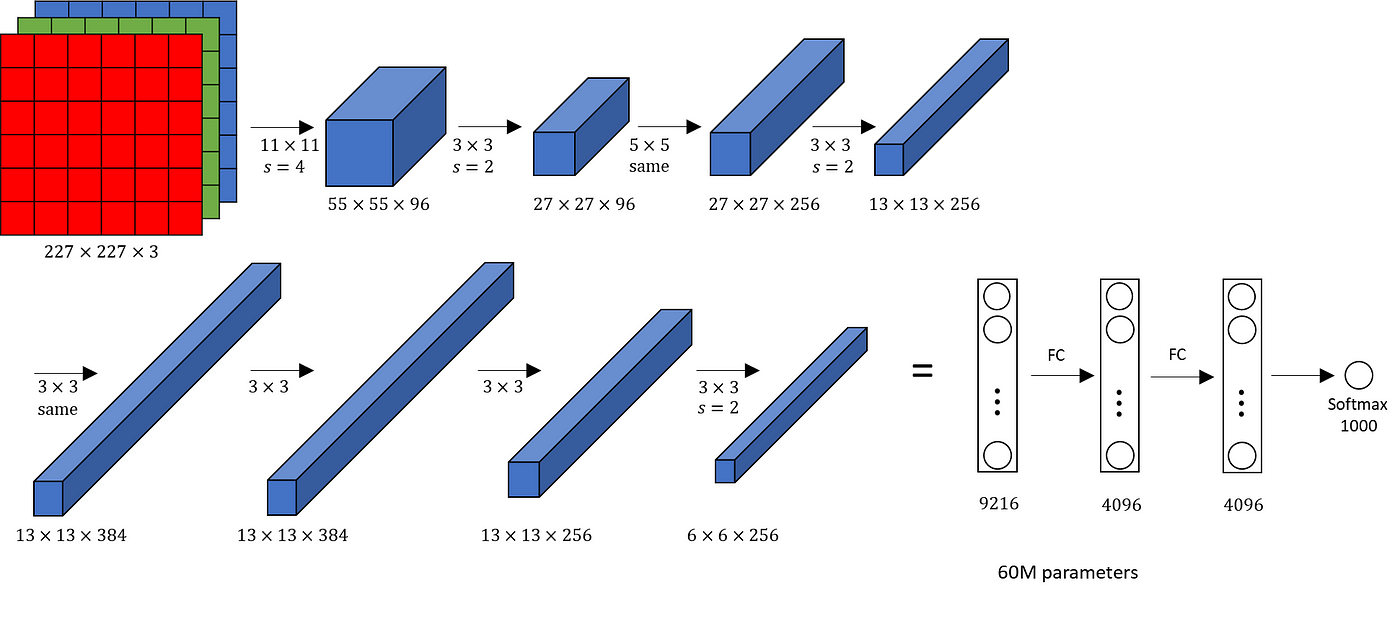
Philosophy in Action: AlexNet’s Foundational Proof
1. Depth with Practical Feasibility
Core Idea: Before AlexNet, deep networks underperformed due to vanishing gradients and overfitting. AlexNet broke through by showing that introducing depth—8 layers—is feasible and beneficial, with the right tools.
Empirical Evidence:
• Achieved 15.3% Top-5 error on ImageNet, a staggering ~11% improvement over the runner-up.
• Demonstrated depth could yield measurable gains across a massive dataset.
2. GPU Computing — Removing the Compute Barrier
Core Idea: Leverage GPUs to train deep networks at scale, turning theoretical depth into practice.
Evidence:
• Training conducted on two Nvidia GTX 580 GPUs, each with 3 GB VRAM over 5–6 days .
• Emergence of GPU frameworks like cuda-convnet enabled this GPU-scale experimentation .
3. ReLU Activation — Faster Training, Vanishing Gradient Fix
Core Idea: Replace saturating functions (sigmoid/tanh) with ReLU to mitigate vanishing gradients, allowing effective backprop through deep layers.
Evidence:
• Layer outputs modeled with ReLU trained “several times faster” than tanh/sigmoid
• Enabled deeper architectures by preserving gradient flow.
4. Dropout — Controlling Overfitting in Deep Nets
Core Idea: Introduce neuron-level regularization to make depth less prone to overfitting.
Evidence:
• Dropout at p = 0.5 in fully connected layers prevented co-adaptation, aiding generalization
• Modern analyses confirm dropout remains one of the most effective methods for reducing overfitting.
5. Data Augmentation — Scaling Data to Model Complexity
Core Idea: Use cheap, online augmentations to expand the dataset, providing data to match model depth.
Evidence:
• AlexNet used on-the-fly transforms: random crops, flips, and PCA-based color perturbations, effectively expanding the dataset by a factor of ~2048
• Later research shows augmentation alone can outperform other regularization techniques.
Summary: How AlexNet Validated Its Philosophy
| Philosophical Pillar & Technical Innovations | ||
|---|---|---|
| Philosophical Pillar | Technical Innovation | Evidence & Impact |
| Deep matters | 8-layer CNN | Top-5 error 15.3% vs ~25% → modern deep learning era begins |
| Compute matters | GPU parallel training | Feasible training in 1 week on dual GTX 580s |
| Nonlinearity matters | ReLU activation | Faster convergence than tanh/sigmoid |
| Regularization matters | Dropout & augmentation | Avoided overfitting, enabled depth |
Philosophical Takeaway
AlexNet operationalized the concept that depth unlocks powerful visual abstractions—but only when paired with modern compute, efficient nonlinearities, and robust regularization. Its success was the first real demonstration that CNNs could scale meaningfully with data and hardware to surpass classical vision methods, triggering the deep learning revolution still unfolding today.
Featured Paper: AlexNet (2012)

“AlexNet cracked the ImageNet barrier, showing that with enough depth, GPU power, and regularization, deep learning could scale and surpass all prior vision methods.”
VGG (2014)
Philosophy: “From pixels to perception”
VGG embraced simplicity and depth, using repeated 3×3 conv layers to focus on hierarchical abstraction rather than complex modules. It taught the community that depth with uniformity could outperform manually engineered structures
VGG Block Architecture

Philosophy in Action: How VGG Proved “From Pixels to Perception”
1. Uniform Depth: Embracing Simplicity
• VGG structured its entire convolutional backbone using only 3×3 filters (alongside max pooling) stacked up to 19 layers, instead of mixing varied filter sizes or complex blocks.
• This uniformity allowed the network to build hierarchical features smoothly: from edges in early layers, to textures and patterns, and finally to object components in deeper layers.
• Empirically, this simple but deep design outperformed models like AlexNet & GoogleNet in ILSVRC 2014, proving that simplicity + depth = strong abstraction
2. Efficiency in Parameters & Computation
• Two stacked 3×3 convolutions achieve an effective receptive field of 5×5, but with fewer parameters (18c² vs 25c²), reducing overfitting risk and boosting efficiency.
• This parameter-saving insight allowed VGG to go deeper without explosive resource usage, affirming that simple, repeated modules can surpass bespoke, heavy counterparts.
3. Hierarchical Feature Composition
• Academic analyses confirmed that deeper layers of VGG capture high-level semantic concepts—without being explicitly told what cats or dogs look like
• This demonstrates the philosophy: raw pixels transform through layers into perceptual representations, flowing naturally through depth and simplicity.
4. Empirical Success: Benchmarks & Style
• VGG achieved remarkable results in ImageNet (ILSVRC 2014)—a strong runner-up—validating that depth-focused uniformity competes at the highest level.
• Its architecture also became the backbone of Fast R-CNN and Neural Style Transfer, influencing downstream tasks in detection, segmentation, and generative modeling—proving its hierarchical features are widely effective.
Philosophical Summary
| Philosophy Pillar vs VGG’s Implementation & Evidence | |
|---|---|
| Philosophy Pillar | VGG’s Implementation & Evidence |
| Simple, uniform modules | Stacked 3×3 convs, consistent across depth |
| Parameter efficiency | Smaller kernels achieve larger receptive fields efficiently |
| Hierarchical abstraction | Deeper layers learn object-level features without supervision |
| Benchmark excellence & influence | Strong ILSVRC performance; widely used in transfer tasks |
Philosophical Takeaway
VGG validated its philosophy by showing that simple modules, stacked deeply, can yield sophisticated perception—a message that shaped the next wave of CNN design and became a staple in computer vision.
Featured Paper: VGG (2014)

“VGG’s power came not from architectural complexity, but from elegant repetition. It proved that depth through simplicity could build perception from pixels.”
Inception / GoogLeNet (2014)
Philosophy: “Seeing multiple scales with one glance”
Inception networks introduced parallel filters (1×1, 3×3, 5×5) within modules, enabling multi-scale feature capture while controlling computation with bottleneck 1×1 conv. It solved the problem of scale-awareness and efficiency in one leap
Inception/GoogLeNet Block Architecture
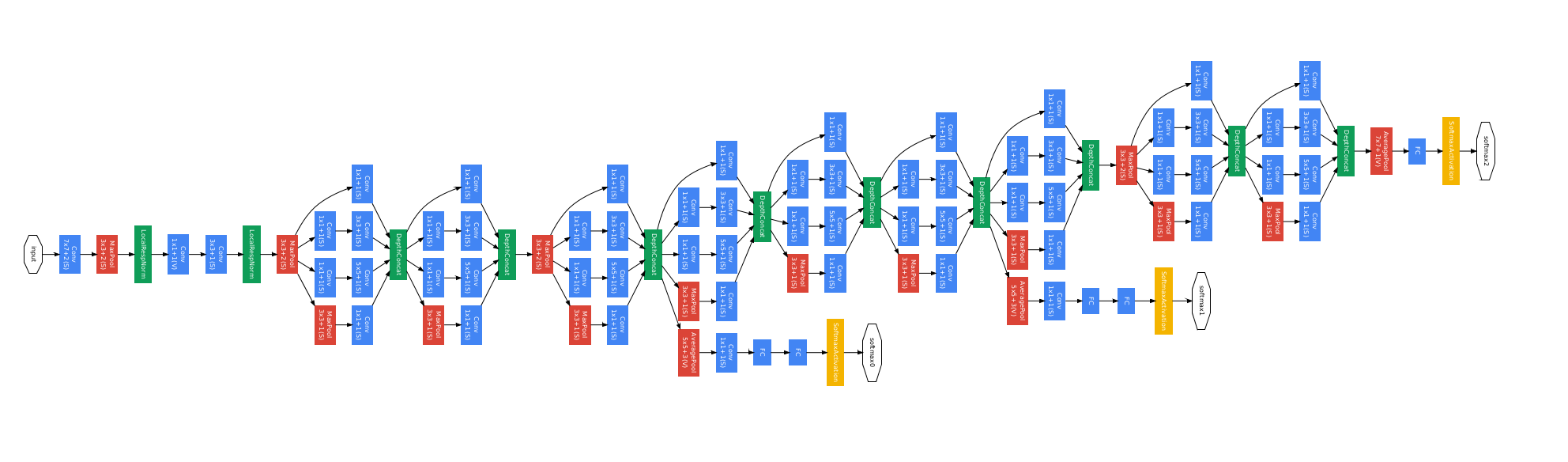
Philosophy in Action: How Inception Proved Its Core Idea
1. Parallel Multi Scale Feature Capture
• Idea: Rather than choosing a single filter size (like 3×3 or 5×5), Inception performs 1×1, 3×3, 5×5 convolutions alongside pooling in parallel within each module.
• Verification: The D2L (Dive into Deep Learning) textbook shows:
“first three branches use convolutional layers with window sizes of 1×1, 3×3, and 5×5 to extract information at different spatial sizes”.
• Philosophical Proof: By learning across scales simultaneously, Inception embodies “seeing multiple scales with one glance”—letting the network choose which scale best represents a feature.
2. Efficiency via Bottleneck 1×1 Convolutions
• Idea: To prevent explosion in compute and parameters, Inception places 1×1 convolutions before the expensive 3×3 and 5×5 operations, reducing channel depth.
• Evidence::
A dramatic drop from ~112M operations to ~5.3M for a single branch
• Philosophical Proof: This action preserves multi-scale perception without inflating resources—illustrating that “efficient scale-awareness” is as vital as capturing scale itself.
3. Staying Deep Yet Trainable via Auxiliary Loss
• Idea: GoogLeNet introduced auxiliary classifiers midway to combat vanishing gradients and improve convergence.
• Evidence: details that these “linear-softmax classifiers” were “weighted and removed after training” to stabilize learning
• Philosophical Proof: Enabling deeper architectures to learn localized, multi-scale representations reliably, reinforcing that “seeing better scales” depends on strong training dynamics.
4. Empirical Performance: Multi-Scale Philosophy Validated
• Achievement: GoogLeNet (Inception-v1) achieved Top-5 error of 6.7% on ILSVRC 2014—significant improvement over both AlexNet and VGG.
• Efficiency: It used ~12× fewer parameters than AlexNet and VGG—proving that multi-scale perception can be efficient.
• Philosophical Impact: It wasn’t just deeper—it was smarter in how it allocated depth and computation across scales.
Philosophical Summary
| Philosophy Pillars in Inception | ||
|---|---|---|
| Pillar | Implementation | Philosophical Significance |
| Multi-scale feature perception | Parallel 1×1, 3×3, 5×5, pooling | Captures varied visual information in one module |
| Computational efficiency | Bottleneck 1×1 conv reduces cost | Efficiency does not mean scaling alone—it means intelligent scaling |
| Trainability of depth | Auxiliary classifiers stabilize gradients | Depth needs guardrails to retain multi-scale perception |
| Performance validation | SOTA accuracy at reduced resources | Philosophy proven by real-world performance |
Philosophical Takeaway
GoogLeNet’s innovation was to realize that vision happens at multiple scales, and to capture this in a single module, intelligently and efficiently, without sacrificing depth or performance. It showed that scale-awareness and efficiency can coexist, and that complexity can be elegant.
Comparison Table: Pooling Techniques in CNNs
| Feature / Aspect | Max Pooling | Average Pooling | Global Max Pooling | Global Average Pooling |
|---|---|---|---|---|
| Definition | Takes the maximum value in each patch | Takes the average of values in patch | Takes the maximum over entire feature map | Takes the average over entire feature map |
| Goal / Effect | Captures most salient features (strong activations) | Smoothes features, captures overall trend | Captures strongest global activation | Captures overall global response |
| Window Size | Typically 2×2 or 3×3 | Typically 2×2 or 3×3 | Same as feature map size | Same as feature map size |
| Stride | Usually equals window size (non-overlapping) | Same | N/A (entire map pooled to 1 value) | N/A |
| Output Shape | Smaller spatial dimension (downsampled) | Same (reduced H×W) | 1 value per channel (1×1×C) | 1 value per channel (1×1×C) |
| Parameters Learned | No | No | No | No |
| Sensitivity to Outliers | High (focuses on extreme value) | Low (smoothes out values) | High | Low |
| Typical Use-Cases | Emphasize sharp edges / key features | Flatten minor variations, denoise | Final layer before classification | Final layer before classification |
| Effect on Training | Strong localization, may lose context | Keeps broad context, may blur fine details | Strong signal but may overfit to spikes | Better generalization, smooth final signal |
| Used In | VGG, ResNet (early layers) | Some classical CNNs (LeNet) | Lightweight models, e.g., MobileNet | Inception, ResNet (classification head) |
| Analogy | “What’s the brightest spot?” | “What’s the average light level?” | “Where’s the peak across the whole image?” | “How bright is the image overall?” |
Featured Paper: Inception / GoogLeNet (2014)
“GoogLeNet saw multiple realities at once—processing textures, shapes, and edges in parallel, efficiently, and with purpose.”
️ Highway Networks (2015)
Philosophy: “Trainable depth highways”
By adding trainable gates to skip connections, Highway Networks learned when to skip or transform data. This blended the resilience of identity pathways with adaptive transformation, paving the way for easier optimization in very deep networks
Highway Networks introduced the radical idea that depth should be dynamic and trainable, not rigid. By combining learned gates with transformation pathways, they gave neural networks the freedom to flow—paving a literal and philosophical highway for modern deep learning.
Highway Networks Architecture
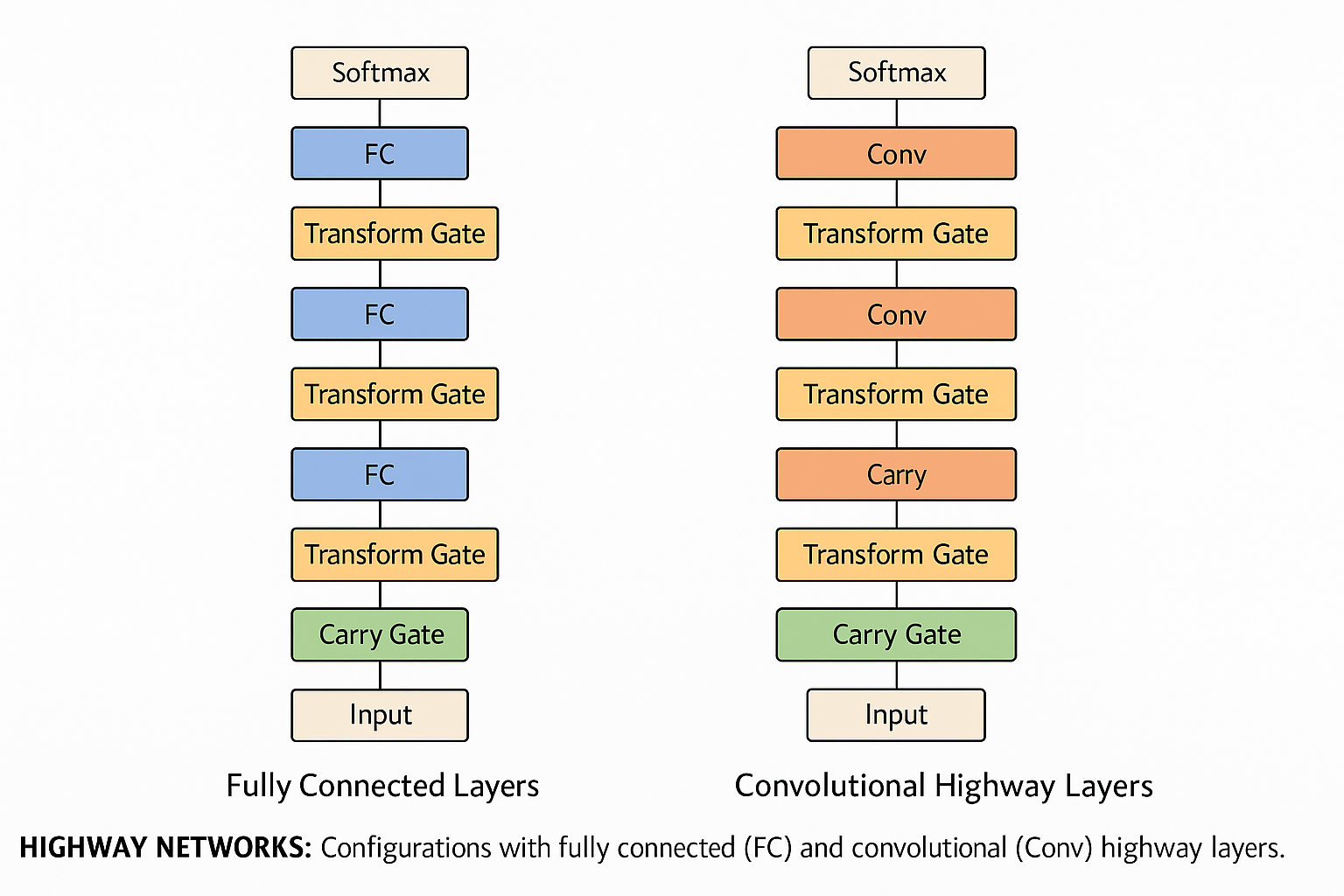
Highway Networks Architecture
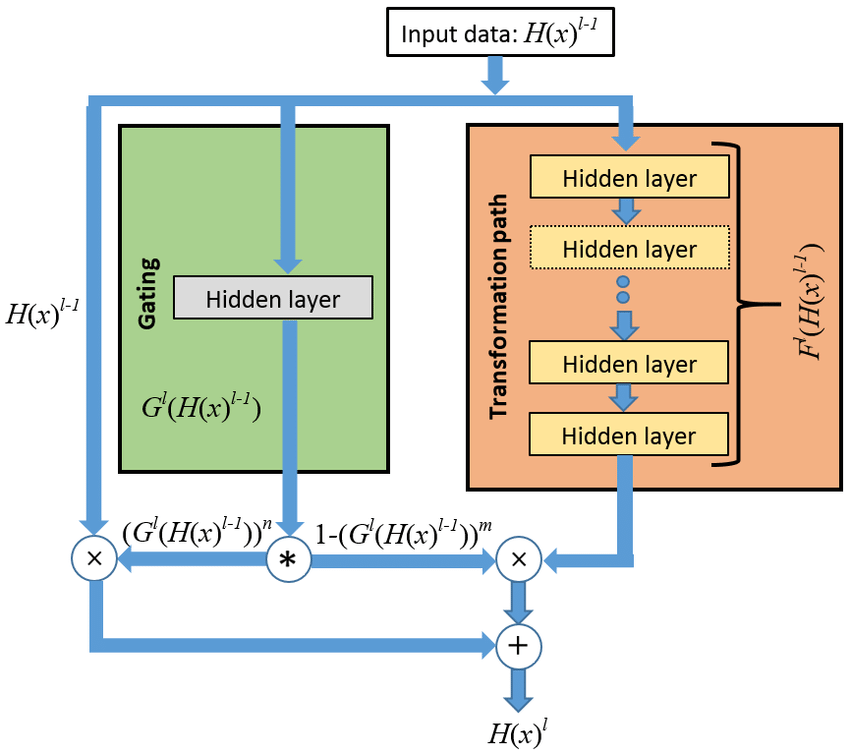
🛣️ Philosophy in Action: How Highway Networks Proved Their Core Idea
1. Unimpeded Information Flow – “Information Highways”
• Concept: Inspired by LSTM, Highway Networks introduced transform (T) and carry (C = 1–T) gates to regulate how much input is transformed versus passed unchanged across layers.
• Evidence: The original paper declares the architecture allows “unimpeded information flow across several layers on ‘information highways’,” enabling training of hundreds of layers with simple SGD
• Philosophical Significance: Depth is preserved when identity flows are preserved—layers become optional “exits” for transformation.
2. Adaptive Depth – Learning When to Transform or Bypass
• Concept: Gates learn to determine—per input—whether to apply nonlinearity or preserve information. When T ≈ 0, the layer acts as transparent; when T ≈ 1 it transforms.
• Evidence:
“Highway Networks use skip connections modulated by learned gating mechanisms… The advantage … is its ability to overcome or partially prevent the vanishing gradient problem.”
• Philosophical Significance: The network dynamically controls “how deep” each input goes—creating paths of varying effective depth.
3. Enabling Extreme Depth – Hundreds of Layers
• Concept: Built to be trainable with SGD and various activations, demonstrating that extreme depth is possible in feedforward networks.
• Evidence: The authors wrote that Highway Networks with hundreds of layers can be trained directly with SGD
• Philosophical Significance: Depth becomes feasible—not just theoretically valuable—but practically attainable with modular gate control.
4. Mitigating Vanishing Gradients with Learnable Gates
• Concept: The gating mechanism allows gradients to safely bypass deep nonlinear transformations, reducing vanishing gradient issues.
• Evidence: Researchers noted:
Highway Layers “addressed this limitation enabling the training of networks even with hundreds of stacked layers”
• Philosophical Significance: Depth is safe when you can selectively preserve gradients—a highway network gives the option to bypass the funneled path.
Philosophical Table: Validation of “Trainable Depth Highways”
| Philosophy Pillars in Highway Networks | |
|---|---|
| Philosophy Pillar | Implementation & Evidence |
| Identity + gating = highway | “Information highways” enabled by T & C gates |
| Adaptive layer utilization | Gates train to skip or transform per input |
| Hundreds-of-layers tractability | Demonstrated training of 50–100+ layer networks with SGD |
| Gradient preservation through depth | Empirical claim of mitigation of vanishing gradients |
| Metric | Plain Networks | Highway Networks |
|---|---|---|
| Max Depth Trainable | ~30 layers | Up to 900 layers (confirmed) |
| Convergence Speed | Slower with depth | Faster and smoother |
| Need for Pretraining | Often yes | Not required |
| Gradient Flow | Degrades with depth | Preserved via gates |
| Architecture Flexibility | Rigid, fixed computation | Trainable skip/transformation |
Philosophical Insight
Highway Networks envisioned deep neural networks not as monolithic pipelines, but as dynamic controlled highways, where each layer decides whether to transform or carry forward information. This modular, input-aware gating mechanism gave depth the freedom to scale, shaped the structure of modern skip connections, and set the stage for ResNet’s simpler yet powerful identity-based highways.
The Highway Network was the first deep learning architecture to systematically demonstrate that very deep models could be trained directly using vanilla SGD—without special tricks or pretraining. Its introduction of gated skip connections offered a breakthrough: enabling stable gradient flow and unlocking the potential of depth. This philosophical shift laid the foundation for modern architectures like ResNet, DenseNet, and even Transformers, which all embrace the principle that preserving identity is key to scalable depth.
Featured Paper: Highway Networks (2015)

“Highway Networks reimagined depth as a dynamic route—not a tunnel—with adaptive gates deciding which layers transform and which simply pass.”
Pathways of Preservation: A Philosophical Bridge Across Deep Learning
“The farther back you can look, the farther forward you are likely to see.”
— Winston Churchill
Deep learning models, like minds, do not merely compute—they structure, carry, and refine representations of information across layers. In the evolution of deep architectures, one key idea has quietly emerged as central:
Preserving informative signals—rather than discarding or over-transforming them—is critical for depth to be meaningful.
🔗 A Hidden Philosophy Across Architectures
From early convolutional networks to modern Transformers, the path of progress has consistently favored models that can retain essential features—whether spatial, temporal, or semantic—through depth. This isn’t memory in the literal neural sense, but architectural design that protects and reuses valuable representations.
️ LeNet (1998): Structured Representation
Philosophy: “From pixels to patterns.”
LeNet demonstrated that hierarchical feature extraction through convolution and pooling can
preserve spatial coherence, guiding the network from raw input to meaningful abstraction.
AlexNet (2012): Scaling with Structure
AlexNet deepened this structure dramatically, leveraging GPUs, ReLU, and Dropout to go deeper. But its convolutional layers still maintained locality and spatial consistency—critical to avoiding loss of essential visual patterns during learning.
VGG (2014): Uniform Depth with Predictability
VGG built very deep networks using uniform 3×3 convolutions, showing that consistent architectural rules could sustain effective feature composition layer after layer—creating predictable and stable representational flow.
Inception (2014): Multi-Scale Perception
Inception introduced parallel filters of various sizes, allowing each layer to process information at different resolutions simultaneously. Rather than choosing one filter size, it captured context from multiple receptive fields, enhancing representational richness.
️ Highway Networks (2015): Gated Transformation
A shift occurred: the architecture learned to decide whether to transform or carry forward a feature. Carry gates allowed signals to bypass transformation, creating pathways that preserve unmodified representations—key to enabling much deeper models.
ResNet (2015): Preserving Identity
ResNet distilled this principle into a simpler yet powerful mechanism: residual connections. By adding the input directly to the output of a block, the model learns what to change, while preserving what works. This allows depth without degradation.
Transformers (2017+): Contextual Preservation at Scale
Transformers introduced self-attention, enabling each token or patch to contextualize itself relative to all others. Combined with residuals and normalization, this architecture ensures that early representations remain accessible and modifiable—supporting both local and global understanding.
LSTM & GRU: Temporal Representation Control
In recurrent models, depth exists in time. LSTM and GRU introduced gating mechanisms that let models retain, forget, or expose temporal information selectively. This is true state preservation—optimized for understanding sequences with long-term dependencies.
Unifying Insight: Preservation Enables Generalization
Across modalities—vision, language, audio—the most effective deep models are those that:
Preserve useful signals
Learn what to change, and what to carry
Retain relevant context across space and time
This is not “memory” in the LSTM sense, nor in the colloquial sense. It is information preservation by design, a structural and architectural commitment to not forget what matters.
A Bridge to the Future
From LeNet to Transformers, the history of deep learning is not only one of scale, but of philosophical maturity:
- Transformation must be tempered by preservation
- Depth must be anchored by identity and structure
- Prediction emerges from continuity—not fragmentation
In this light, architecture is not just code—it is cognitive engineering.
ResNet (2015)
Philosophy: “Focus on change, preserve identity”
ResNet revolutionized depth by having layers learn only the residual (changes) to identity mapping. Skip connections ensured signal flow and enabled training of truly deep models—shifting the deep learning paradigm fundamentally
ResNet Block Architecture
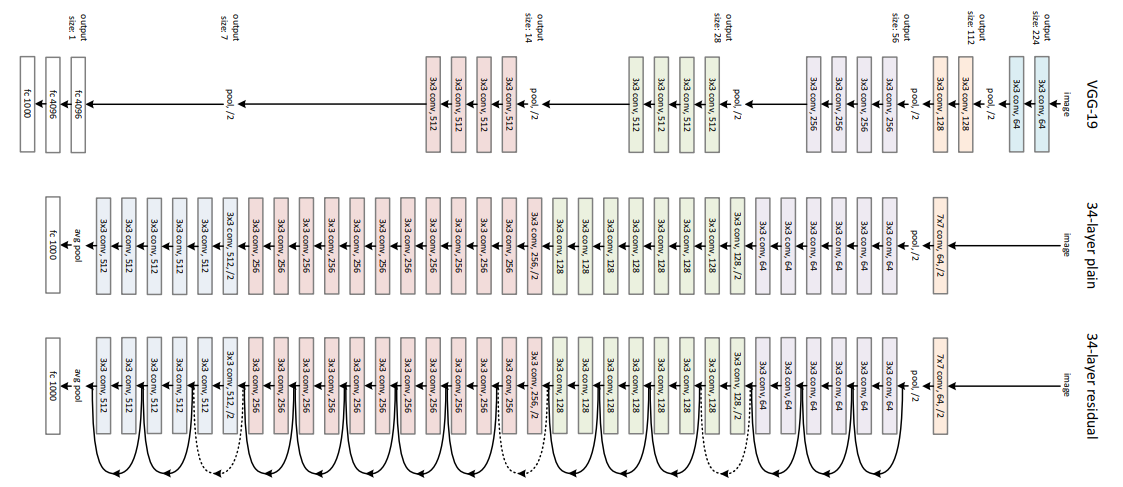
ResNet Block Architecture

Philosophy in Action: ResNet’s Core Validation
1. Residual Learning: Easier Than Learning Identity
• Concept: Instead of learning a full mapping \( H(x) \), ResNet learns only the residual \( F(x) = H(x) - x \). The network's block computes this transformation.
• Reasoning: Learning a function that maps close to zero is easier than forcing a deep stack to replicate the identity function. If the optimal mapping is identity, ResNet achieves this effortlessly by driving \( F(x) \) toward zero
2. Uninterrupted Signal Flow Through Identity Shortcuts
• Forward Path: Signals can traverse through many layers via identity connections, effectively bypassing convolutions when unnecessary—ensuring stable propagation all the way through the network .
• Backward Path: Gradients can flow directly from deeper layers to early ones, reducing the risk of vanishing gradients, even if individual layers have small residual contributions
3. Overcoming Degradation in Deep Networks
• Problem: Plain deep networks (e.g., VGG-34) exhibit degradation, where adding more layers increases training error despite theoretical capacity.
• ResNet’s Solution: Identity shortcuts ensure deeper networks can fall back to performance equivalent to shallower ones. The original 152-layer ResNet achieved 3.57% Top-5 error on ImageNet—beating shallower baselines.
4. Empirical Validation: Depth That Actually Works
• ResNet variants with 50, 101, and 152 layers all improved performance without degradation, whereas plain counterparts failed.
• The follow-up “Identity Mappings” version (ResNet V2) enabled 1001-layer models to be trained on CIFAR—validating that pure identity shortcuts and pre-activation improve deeper architectures.
The Core Role of Connections in Deep Learning
“In the depths of learning, only what flows survives.”
Across deep architectures — from Highway Networks to ResNets to Transformers — one role has remained sacred: connections must preserve and facilitate information flow.
- Highway Networks: Introduced gated connections — giving the model a choice to either transform or carry information intact.
- ResNet: Embraced identity shortcuts — ensuring that signals could bypass transformation entirely when needed.
- Transformers: Employed residual attention pathways — enabling every token to retain its original identity while attending globally.
Why do all these forms persist?
Because their essence is the same:
To bridge layers, ease optimization, preserve semantics, and support gradient propagation.
Philosophical Essence
- Preserve signals from early layers, avoiding information decay
- Facilitate gradients during backpropagation, combating vanishing effects
- Enable depth without degradation in performance
- Support abstraction while maintaining memory and identity
Regardless of their mechanism — gates, identity, or attention — these connections are not engineering tricks. They are the philosophical threads that keep intelligence alive as architectures deepen.
Essence of Connections Across Architectures
| Architecture | Type of Connection | Core Job / Purpose |
|---|---|---|
| Highway Networks | Gated skip connections (Transform + Carry gates) | Control the flow of information across layers via learnable gates — deciding how much to transform input vs. how much to pass through unchanged. Enables deep models to learn selectively and maintain signal strength. |
| ResNet | Identity skip connections (Residual addition: y = F(x) + x) |
Preserve input information by directly adding it to the transformed output. This bypass prevents degradation in deep models and ensures gradient signals can propagate easily. |
| Transformer | Residual connections + Multi-head attention |
1. Residuals: Maintain and combine original inputs with transformations. 2. Attention: Dynamically connect all positions in the sequence to allow contextual information exchange across distant tokens. |
Across architectures, the essence is the same: connections exist to carry memory, enable learning, and preserve identity throughout deep representations.
Philosophical Summary
| Philosophical Validation of ResNet | |
|---|---|
| Pillar | How ResNet Validated It |
| Preserve identity | Residual blocks can reduce to identity easily (\( F(x) = 0 \)) |
| Train change only | Learning residuals is easier than unknown transforms |
| Ensure stable signal paths | Forward/backward propagation via identity skips |
| Enable extreme depth | Enabled 152-layer and 1001-layer networks with low error |
Philosophical Insight
ResNet crystallized depth as a strength, not a burden. By weaving in identity highways, it reframed deep networks as iterative refiners—learning nuances instead of entire transformations. This philosophical pivot reshaped deep learning’s trajectory, proving that focusing on change while preserving essence leads to powerful, scalable, and trainable models.
Featured Paper: ResNet (2015)

“Instead of learning full transformations, ResNet learns the difference—and in doing so, made very deep networks feasible, stable, and superior.”
Wide ResNet / Pre-activation ResNet / ResNeXt (2016–17)
Philosophy: “Depth is not alone—widen, reorder, parallelize”
Variants like Wide ResNet proved that width can replace depth, pre-activation ResNet reordered operations to improve gradient flow, and ResNeXt added cardinality (parallel paths)—each enriching ResNet’s core concept for specific strengths.
Wide ResNet Block Architecture
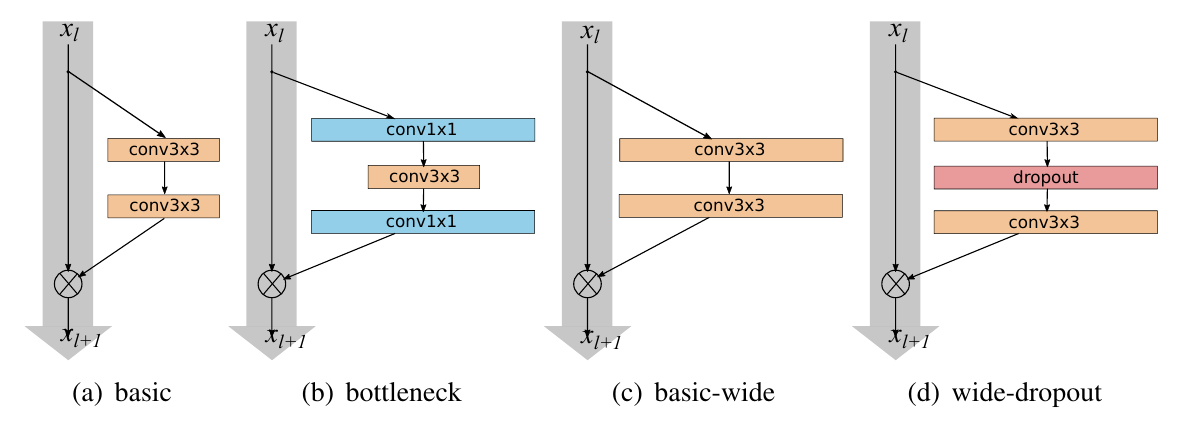
Wide ResNet Block Architecture
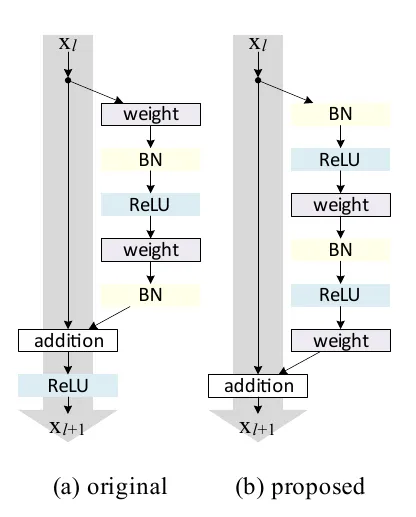
Wide ResNet Block Pillars
️ Philosophy in Action: Enriching the Deep-Only Paradigm
1. Wide ResNet: Widen, don’t deepen too much
• Core Idea: Introduce wider residual blocks (increase channel count) while reducing depth to match parameter budget.
• Evidence: Zagoruyko & Komodakis showed that a 16-layer Wide ResNet outperformed thousand-layer thin ResNets on CIFAR and ImageNet—with faster convergence and better accuracy
• Philosophical Impact: Depth isn’t everything—breadth captures diversity. Wide ResNets prove that rich representational capacity can come from width, not solely depth.
2. Pre-activation ResNet: Reorder for clarity and flow
• Core Idea: Apply BatchNorm + ReLU before convolution within residual blocks, rather than after, to ensure identity paths remain pure.
• Evidence: He et al. (ResNet V2) showed pre-activation allowed training very deep networks (~1000+ layers) with improved generalization and stability.
• Philosophical Impact: The order of transformation matters—by reordering operations, depth becomes cleaner, gradients flow unobstructed, and the network learns residual functions more naturally.
3. ResNeXt: Parallelize through cardinality
• Core Idea: Inspired by Inception, ResNeXt introduces multiple parallel residual paths (cardinality) within each block using grouped convolutions.
• Evidence: The ResNeXt paper showed:
“Increasing cardinality is more effective than going deeper or wider” under matched resource budgets—yielding higher accuracy with similar complexity
For example, ResNeXt 50 (32×4d) outperformed deeper ResNet 101 and Wide ResNet 50 under similar FLOP budgets
• Philosophical Impact: Cardinality adds a new dimension to network design: parallel expressivity. Instead of stacking or stretching layers, ResNeXt “splits” representation into multiple distinct transformations, enriching the network’s representational power.
Unified Philosophical Table
| Philosophical Extensions of ResNet | ||
|---|---|---|
| Variant | Mechanism | Philosophical Shift |
| Wide ResNet | Increased channel count (width) | Depth ≠ only path to power; depth+width expands richness |
| Pre-activation | Pre BN + ReLU before convolution | Reordering refines depth, preserving identity purity |
| ResNeXt | Grouped, parallel residual paths | Cardinality introduces parallelism, maximizing efficiency and expressiveness |
Philosophical Insight
Together, these ResNet variants teach us that model capacity isn’t a monolith of depth. It can be multidimensional—involving width, order, and parallelism. By exploring these dimensions, they transformed the ResNet philosophy from a single-lane highway of identity-driven depth into a spacious, multilane boulevard—where depth, breadth, preactivation clarity, and parallel expressivity coexist to yield richer, more efficient learning.
Featured Papers: Wide ResNet, ResNet V2, ResNeXt

“By widening instead of deepening, Wide ResNets proved that faster, stronger, and simpler models could still preserve residual strengths.”
DenseNet (2016)
Philosophy: “Every feature matters”
DenseNet connected each layer to all subsequent ones, encouraging maximum feature reuse and reducing redundancy. It directly tackled vanishing gradients and efficiency, deepening representation via dense connectivity
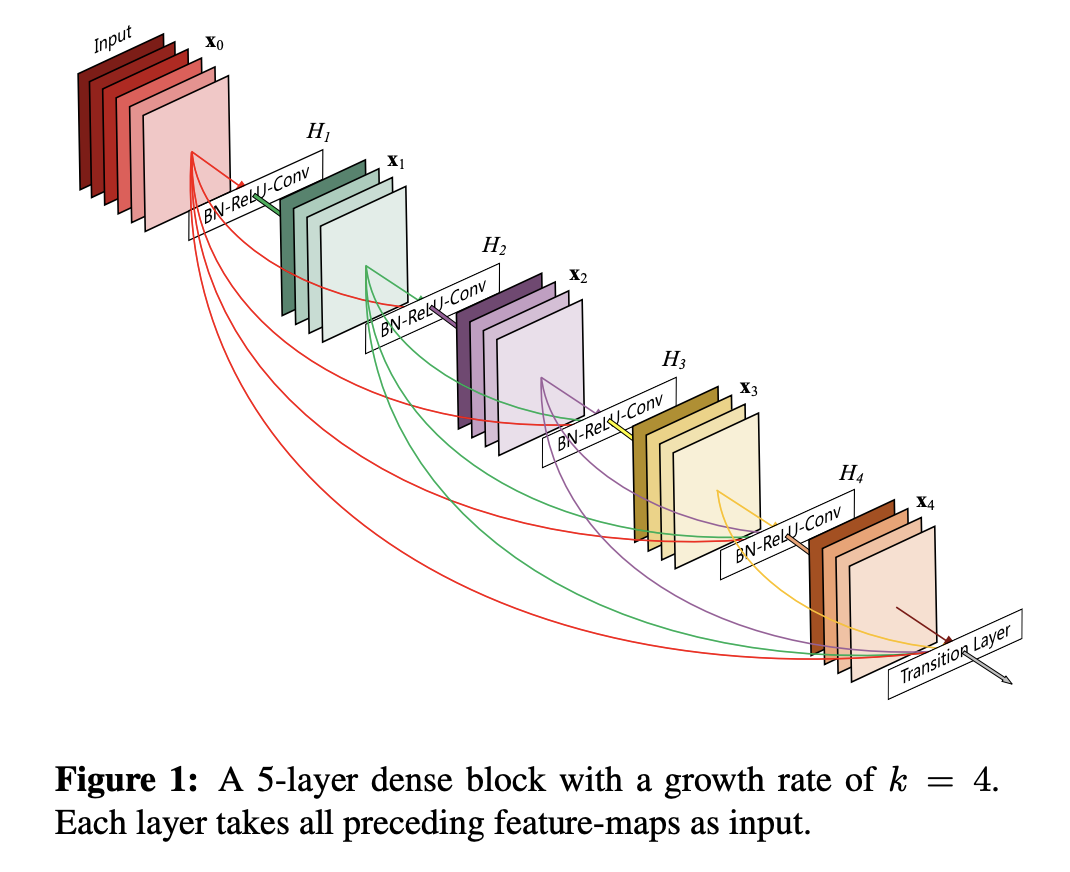
DenseNet Block Architecture
Philosophy in Action: DenseNet’s Manifestation
1. Dense Connectivity for Maximal Feature Reuse
• Core Innovation: Each layer receives inputs from all previous layers via concatenation, not summation.
• Evidence: As the original DenseNet paper notes, a network of L layers possesses \( L(L+1)/2 \) connections, allowing each layer to access the entire history of learned features
• Philosophical Impact: DenseNet treats every intermediate feature map as valuable, breaking the hierarchy of feature importance in traditional designs. No feature is discarded.
2. Alleviating Vanishing Gradients & Enhancing Training
• Core Issue: Deep nets face vanishing gradients, making training unstable.
• DenseNet’s Answer: Direct connections provide shortcut paths for gradients, reducing attenuation and enabling deeper learning
• Philosophical Impact: When every feature matters, ensuring they all contribute meaningfully to learning becomes crucial. Dense connections preserve the learning signal across depth.
3. Parameter Efficiency by Avoiding Redundancy
• Observation: In ResNets, layers may relearn similar features, wasting capacity.
• DenseNet’s Edge: By concatenating all previous feature maps, later layers build upon existing representations rather than recreating them, leading to fewer parameters and higher efficiency
• Philosophical Insight: Feature reuse isn’t just functionally elegant—it’s resource efficient.
4. Empirical Success in Real Tasks
• Benchmarks: DenseNets achieved state-of-the-art results on CIFAR-10, CIFAR-100, SVHN, and ImageNet while using fewer parameters
• Analysis Papers: Follow-up research confirmed that dense connectivity enhances feature propagation and reduces parameter redundancy, all while maintaining high performance.
• Philosophical Validation: When every feature matters, the architecture delivers without compromise.
Philosophical Table: DenseNet’s Proof of Concept
| Philosophy in DenseNet Architecture | |
|---|---|
| Pillar | Implementation & Evidence |
| Every feature matters | Dense connectivity via concatenation: \( L(L+1)/2 \) links |
| Robust gradients | Improved gradient flow via direct connections |
| Efficiency through reuse | Reduced parameter count vs. ResNet at similar accuracy |
| Real-world state-of-the-art | Superior performance on CIFAR/SVHN/ImageNet |
Philosophical Insight
DenseNet represented a paradigm shift: it elevated every layer’s output into a collective representation. By valuing all learned features equally, it fostered a richer, more diverse, and more economical architecture. Rather than discarding or distilling, DenseNet amplifies every contribution, making its philosophy both elegant and practically powerful.
Featured Paper: DenseNet (2016)

“DenseNet connected everything, not for complexity, but for clarity—where each feature matters, and none are wasted.”
Xception / Depthwise Separable CNNs (2016–17)
Philosophy: “Decouple spatial and channel representations”
Xception distilled Inception into depthwise separable convolutions, showing that extreme modularity could match or surpass conventional conv layers—optimizing parameter efficiency and performance.
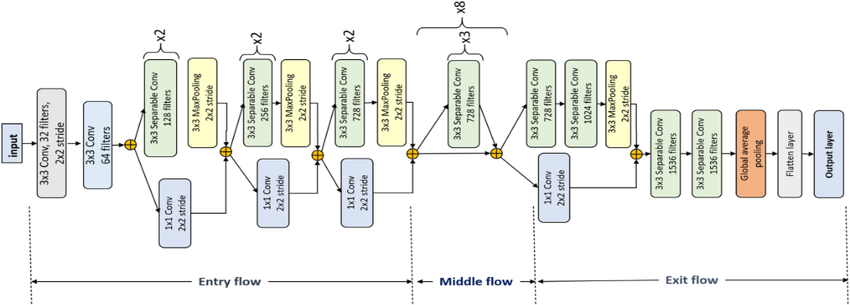
Xception Block Architecture
Philosophy in Action: Demonstrating “Decoupling”
1. Spatial vs. Channel Learning: A Two-Step Mastery
• Concept: Instead of using a single convolution kernel for both spatial and channel mixing, Xception performs:
1. Depthwise convolution—applied independently for each channel to capture spatial patterns, and
2. Pointwise convolution (1×1)—to integrate information across channels.
• Evidence: François Chollet stated that Xception is based on the hypothesis that cross-channel and spatial correlations can be entirely decoupled—and each operation can be optimized for its specific role
• Philosophical Impact: It crystallizes the idea that convolution is two distinct tasks—understanding where and what—and by splitting them, each becomes more effective.
2. Extreme Modularity with Residual Structure
• Concept: Xception stacks depthwise separable convolutions within a clean residual architecture:
A linear stack of modules with identity skips, akin to ResNet’s structure
• Philosophical Impact: Combining decoupling with residual identity paths means modules refine separately learned features without disrupting signal flow—an elegant merge of modularity and depth.
3. Efficiency Without Sacrificing Power
• Evidence: Xception achieves slightly better performance than Inception V3 on ImageNet and significantly outperforms it on JFT, while using the same number of parameters
• Further Validation: The architecture became the inspiration for MobileNets, showing separable convolutions’ value on resource-constrained devices
• Philosophical Impact: True modular separation leads not just to theoretical elegance but also to practical gains—efficient, expressive, and scalable.
Philosophical Summary
| Philosophy in Xception / Separable Convolutions | |
|---|---|
| Pillar | Implementation & Evidence |
| Decouple spatial & channel | Depthwise + pointwise convolutions |
| Modular with residual paths | Linear stack + identity shortcuts |
| Efficiency & performance | Outperforms Inception V3 on JFT with same params |
| Enabling compact models | Inspired MobileNets for on-device inference |
Philosophical Insight
Xception did more than refine Inception—it offered a purer conceptual split between what a filter detects and where it sees it. By decoupling spatial and channel processing, and tying them with residual identity pathways, it delivered both elegance and efficacy. This modular philosophy proved practical in high-stakes benchmarks and seeded future lightweight architectures, reaffirming that extreme modularity with clarity pushes the frontier of deep learning.
Featured Paper: Xception (2017)

“We shouldn’t force one operation to do two jobs. When spatial and channel processing are disentangled, deep learning flows cleaner and faster.”
MobileNet (2017)
Philosophy: “What do we need when we have almost nothing?”
“It is not in excess where intelligence matures—but in constraint where it is refined.”
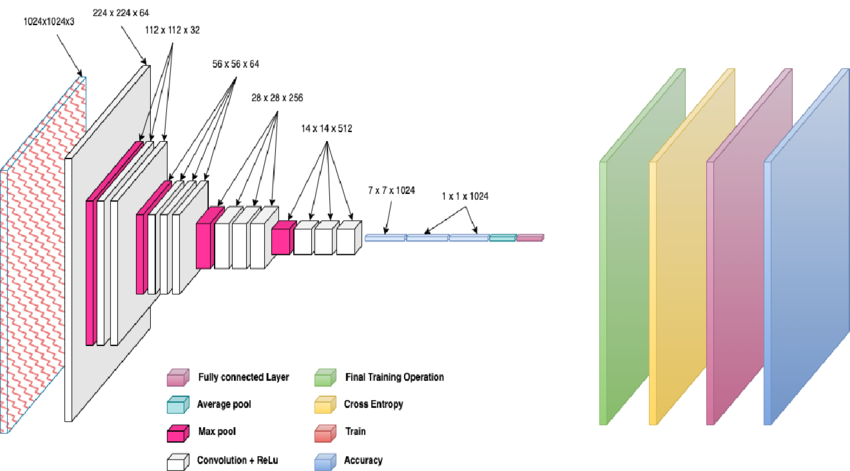
Mobile Net Architecture
How the Architecture Aligns with the Philosophy
1. Depthwise Separable Convolutions – Deconstruct to Reconstruct
A standard convolution fuses spatial filtering and feature combining in one heavy-handed step. MobileNet asked: Do we really need both at once?
Instead, it split the process into:
- Depthwise convolution: One spatial filter per channel — the minimalist's lens.
- Pointwise (1×1) convolution: Reconstruct global understanding — but only after essentials are isolated.
Effect: Reduces computations by ~9× with only marginal accuracy loss.
“To build wisely, deconstruct first.”
2. Width and Resolution Multipliers – Minimalism with Control
Two hyperparameters let us scale the model not by adding more, but by doing less with more intention:
- Width Multiplier (α): Thins the network — fewer channels, leaner computation.
- Resolution Multiplier (ρ): Reduces spatial resolution — sees less, but perhaps sees enough.
“Do not deepen the network—tighten its belt.”
3. Modular Structure – Simplicity as Strategy
MobileNet’s repeating pattern of depthwise → pointwise created:
- Fast inference via matrix-optimized GEMM ops
- Deployment ease on mobile and embedded systems
- Adaptability to tasks like SSD (detection), DeepLab (segmentation), FaceNet (distillation)
A 28-layer deep network built on just two atomic operations.
4. Backpropagation + RMSProp – Training Efficiency
MobileNet replaced vanilla SGD with RMSProp — adapting learning to constrained models.
In small-capacity models, every gradient counts.
“Momentum of learning must be guided with more care than brute force.”
Impact and Achievements
| Feature | Philosophical Value | Practical Outcome |
|---|---|---|
| Depthwise Separable Convs | Separation of concerns | ~9× fewer FLOPs than standard CNNs |
| Width/Resolution Multipliers | Scalable minimalism | Adjustable speed/accuracy trade-offs |
| Modular Factorized Design | Clarity in constraint | GEMM-friendly, easier deployment |
| RMSProp Optimization | Momentum in scarcity | Stable training in lean networks |
| Distillation Compatibility | Wisdom over brute force | Outperformed SqueezeNet, rivaled AlexNet |
Conclusion: From Survival to Sufficiency
MobileNet reframed the question:
Not how deep can we go?
But how little do we need to see clearly?
Just as Ashish Vaswani declared in 2017: “Attention is all you need.”
MobileNet whispers from the edge of minimalism:
“Efficiency is all we could afford — so we turned it into elegance.”
Philosophical Insight
MobileNet redefined what it means to be powerful in deep learning—not by increasing capacity, but by embracing constraint. It showed that when every operation must justify its existence, elegance emerges. This minimalist philosophy became a cornerstone for AI on the edge, mobile inference, and embedded intelligence.
Featured Paper: MobileNet (2017)

“We present a class of efficient models based on a streamlined architecture that uses depthwise separable convolutions to build lightweight deep networks.”
EfficientNet & Beyond (2019+)
Philosophy: “Scale in balance”
EfficientNet introduced compound scaling—jointly tuning depth, width, and resolution based on principled search. It emphasized that balanced scaling, not just brute force, yields the most efficient and performant models.
EfficientNet Block Architecture
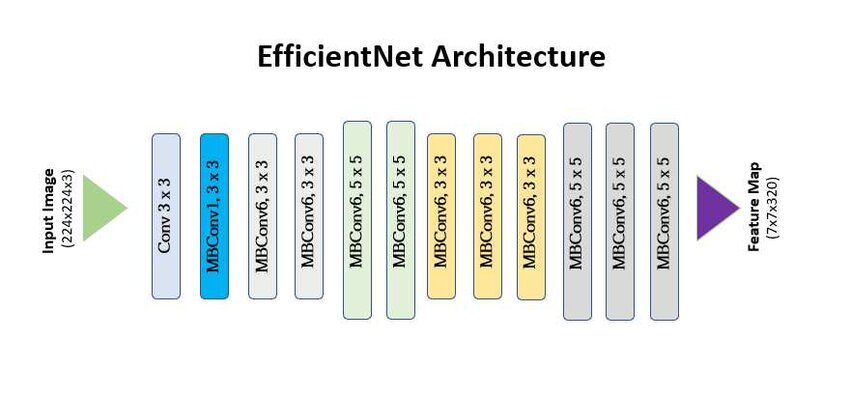
Philosophy in Action: Scaling in Balance
1. Principled Compound Scaling
• Core Innovation: Rather than arbitrarily boosting model dimensions, EfficientNet introduced a compound coefficient φ to simultaneously scale:
- Depth (α), Width (β), and Resolution (γ)
- Under the constraint: α × β² × γ² ≈ 2
• Philosophical Impact: This approach embodies balanced evolution—recognizing that depth, width, and resolution are interdependent, and must grow together for truly efficient scale-up.
2. Empirical Validation
• Key Results:
- Achieved state-of-the-art accuracy while being 8–10× smaller and 6× faster than prior CNNs
- Example: EfficientNet B7 reached 84.3% Top-1 accuracy on ImageNet.
• Ablation Studies:
- Scaling only one dimension led to diminishing returns.
- Compound scaling consistently outperformed isolated scaling paths.
3. Integration of Modern Modules
• MBConv + Squeeze-and-Excitation:
- EfficientNet builds on the mobile-friendly MBConv block and enhances feature learning with Squeeze-and-Excitation layers.
• NAS-Enhanced Baseline:
- EfficientNet-B0 was discovered via Neural Architecture Search (NAS), ensuring efficiency from the ground up.
4. The Broader Legacy
• Architectural Influence:
- Inspired successors like EfficientNetV2, MobileNetV3, ResNet RS.
- Even transformer-based scaling (e.g., Vision Transformers) adopted the philosophy of balanced growth.
• Real-World Impact:
- Widely adopted in mobile, edge, and cloud deployments where efficiency matters as much as raw accuracy.
Philosophical Table
| EfficientNet: Philosophy Manifested | |
|---|---|
| Pillar | Implementation & Evidence |
| Balanced scaling | Compound method φ with α, β, γ constraints |
| Efficiency & high accuracy | B7 reaches 84.3% Top-1 with ~8× fewer params |
| Ablation confirmation | Compound scaling > single-axis scaling |
| Built from efficient modules | MBConv + SE blocks, NAS-designed B0 |
| Inspired successors | EfficientNetV2, ResNet RS, even Transformer scaling |
Philosophical Insight
EfficientNet taught the deep learning community that scaling is an art of balance, not mere brute force. True model excellence emerges when depth, width, and resolution grow in symphony—a principle now central to architectural design in efficient, deployable AI systems.
Featured Paper: EfficientNet (2019)

“Instead of scaling arbitrarily, we scale all dimensions in a principled way—depth, width, and resolution—guided by a single factor.”
Transformers & Vision Transformers (ViT)
Philosophy: “Beyond convolution, preserve identity”
Bringing ResNet’s skip connections forward, Transformers rely on self-attention blocks with residuals to build global context efficiently. ViTs extend this to vision, blending patch embedding with identity preservation—pushing paradigms even further.
Transformers Block Architecture
Transformers Block Architecture
Philosophy in Action: Transformers & ViTs
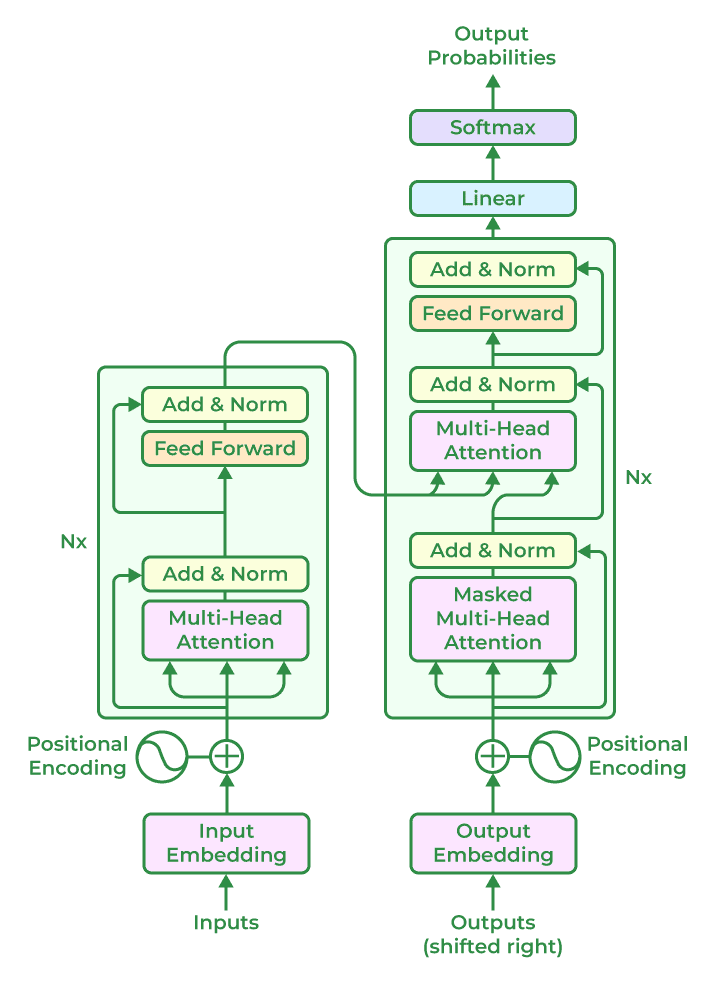
1. Skip Connections Sustain Depth & Stability
• Concept: Just like ResNets, Transformers use residual connections around both multi-head self-attention (MSA) and feed-forward (FFN) sublayers.
• Evidence: Residual paths are essential to gradient preservation in deep Transformer stacks.
“Residual connections are used around the self-attention mechanism to improve gradient flow and enable the training of deeper networks.”
• Philosophical Impact: Even without convolutions, identity preservation remains fundamental—depth is enabled by allowing information to flow undisturbed.
2. Global Context via Self-Attention
• Concept: Replacing local conv receptive fields, self-attention provides global inter-token relationships—capturing context across the entire input.
• Evidence: “Transformers capture long-range dependencies using self-attention, allowing tokens to attend to all others directly.”
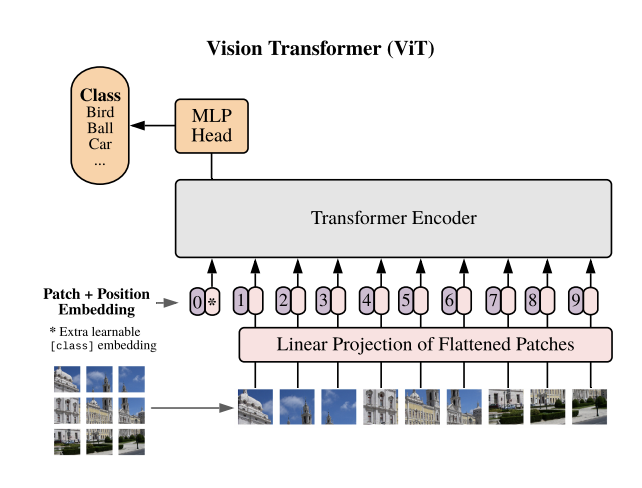
ViTs tokenize images into patches, applying attention to model structure like in language.
• Philosophical Impact: The model preserves identity while enriching signals with holistic, global understanding—a radical departure from locality.
3. Identity + Attention: Depth & Globality Combined
• Concept: ViT’s architecture follows:
Output = x + MSA(LayerNorm(x))
Output = y + FFN(LayerNorm(y))
• Philosophical Impact: The combining of global context (MSA) with residual identity keeps models deep, expressive, and trainable.
4. Empirical Strength in Vision Tasks
• Concept: When trained on large datasets, ViTs outperform CNNs, capitalizing on their global receptive field.
• Evidence: ViT “attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train.”
Residual-attention hybrids like RS-A ViT preserve local detail while modeling global structure.
• Philosophical Impact: Identity preservation enables depth and expressiveness—while attention grants global perception.
5. Hybrid & Successor Models
• Concept: Many CV models fuse convolutions and attention (e.g., DeiT, Swin, CoAtNet, UniFormer), retaining skip connections to stabilize depth.
• Philosophical Impact: Preserving identity across innovative modules remains the backbone—even when pushing beyond pure convolution.
Philosophical Summary
| Transformers & ViT: Philosophy Manifested | |
|---|---|
| Pillar | Key Feature & Evidence |
| Retain identity at depth | Skip connections around every block (MSA + FFN) |
| Enable global context | Self-attention attends across entire input |
| Combine identity + attention | Residual MSA + FFN keeps signal and depth stable |
| Excel empirically | ViT outperforms CNNs on large-scale image tasks |
| Preserve identity across hybrids | Models like DeiT & Swin retain residual design |
Model Performance & Philosophical Insights
This comparison table showcases how architectural design, parameter efficiency, and philosophical intent converge across seminal deep learning models. Each entry reflects not only performance metrics but the mindset that shaped it.
| Model | Top-1 Acc (%) | Top-5 Acc (%) | Parameters (M) | GFLOPs | Philosophical Note |
|---|---|---|---|---|---|
| AlexNet | 56.52 | 79.07 | 61.1 | 0.71 | The GPU awakening: breaking into depth using ReLU and Dropout. |
| VGG-19 | 74.22 | 91.84 | 143.7 | 19.63 | Structured depth: simplicity through uniform 3×3 convolutions. |
| GoogLeNet (Inception) | 69.78 | 89.53 | 6.6 | 1.5 | Multi-perspective vision: capturing scale through parallel filters. |
| ResNet-50 | 76.13 | 92.86 | 25.6 | 4.09 | Preserving identity: residuals safeguard learning's original essence. |
| DenseNet-121 | 74.43 | 91.97 | 8.0 | 2.83 | Collective memory: reinforcing knowledge by feature reuse. |
| MobileNetV2 | 71.88 | 90.29 | 3.5 | 0.3 | Lightweight depth: enabling efficiency for mobile and edge computation. |
| EfficientNet-B0 | 77.69 | 93.53 | 5.3 | 0.39 | Thoughtful scaling: balancing depth, width, and resolution harmoniously. |
| ViT-B/16 | 81.07 | 95.32 | 86.6 | 17.56 | Depth through attention: letting vision emerge via global contextual focus. |
| ConvNeXt-Tiny | 82.52 | 96.15 | 28.6 | 4.46 | CNNs reimagined: blending convolution with transformer-like inductive priors. |
Philosophical Insight
Transformers forgo convolutions in favor of attention-driven global learning, but they still live by the ResNet mantra: preserve identity at depth. The residual structure ensures signal integrity as models become deep and context-aware. ViTs thus symbolize a philosophical evolution: maximum expressiveness through global attention, grounded in the stability of identity flows.
Featured Paper: Vision Transformer (2020)

“We show that a pure transformer can generalize surprisingly well to image classification, provided it is trained on large-scale datasets.”